ToyKV teaser
Here’s a teaser of my followup to the build your own database index series. It’s the most minimal key value store you can write, and is extremely not useful. It does almost nothing you’d want an actual place you put data to do:
- Doesn’t bother checksumming any data. Bit flips for the win!
- Opens files every time it reads or writes them. Every. Single. Time.
- Makes no attempt at all to compress data. Keys and values are just streamed to disk in all their bloated glory.
- It’s an LSM “tree” with just one branch of SSTables.
- And those SSTables are never compacted, and eventually you run out of them.
And it does none of those things so I have a chance to explain it in a reasonable number of words. For that purpose I think I’ve been successful. With a bit of code cleanup, it should be a decent pedagogical tool.
Here’s the main library code to give an idea of just how simple it is:
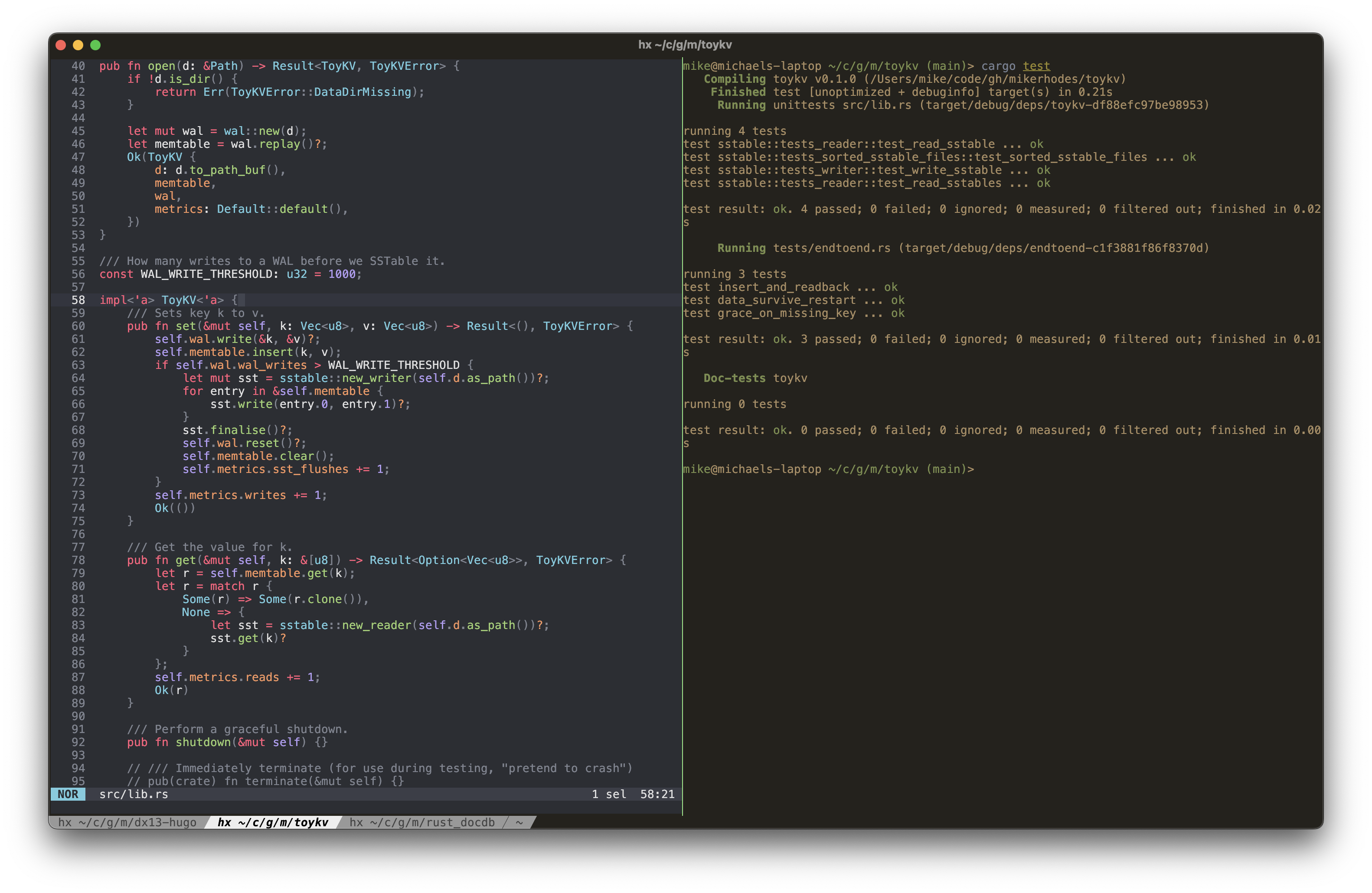
You can see how little data safety matters by (a) the complete lack of error handling, and (b) that the whole database has only seven tests. Put on your hard hats, and prepare for falling rocks 👷
But even with its general awfulness, I’m still excited about having written something that can store and read back stuff in a way that’s not completely trivial. More importantly, writing it has given me the foundation for learning the ways to write a better LSM tree data store.
While you wait for me to write about ToyKV, you can find the code at mikerhodes/toykv.
BYODI 5: plan, optimise, execute 🚀
Welcome to part 5 of the build your own database index series! This was supposed to be about finding documents, but I kind of got ahead of myself in the code, so we will skim over some of the details of finding documents and instead talk about moving from a naive query execution to a (very slightly) more sophisticated two-stage process:
- The query planner takes the caller’s query and creates physical operations from it. Physical operations in this case are index scans — instructions to return document IDs between a start and end key in the index.
- The query executor takes the list of index scans produced by the planner and executes them, creating a final list of document IDs by intersecting the results from each scan.
The original search_index method mangled these two stages together. It also
performed no pre-processing of the query, and naively executed each predicate in
the query exactly as they were passed in.
We can do better than that. Once we have extracted the planning and execution phases into their own methods, we’ll look at performing a simple optimisation of the index scans we do when performing a query.
Arboreal Labyrinth
I loved the idea and execution of this artwork, Corupira, an installation centred on the idea of enchanted forests.

See more photos, and a video on how it was constructed at Henrique Oliveira’s Arboreal Labyrinth Ruptures the Entrance to an Enchanting Exhibition. The installation is part of an exhibition at Brisbane’s Gallery of Modern Art, Fairy Tales: Remixed & Remade.
The rise of the internet’s middle class
I participated in the chaos of MySpace, and remember the disappointment in seeing much online activity move to the hermetically-sealed, sterile environment of Facebook, Twitter and so on.
the “proud extroversion” of the early Web soon gave way to a much more homogenized experience: hundred-and-forty-character text boxes, uniformly sized photos accompanied by short captions, Like buttons, retweet counts, and, ultimately, a shift away from chronological time lines and profile pages and toward statistically optimized feeds. The user-generated Web became an infinite stream of disembodied images and quips, curated by algorithms, optimized to distract.
Back in 2008, 1,000 true fans posited that with just a thousand or so people willing to regularly pay for creations, a reasonable living could be made from creating things on the web. This was, however, before Facebook, Twitter and the rest stole away the monetisation of our content and kept the proceeds for themselves.
With the decline in trust in these platforms, and the realisation that there was money to be made, but only if one left the walled garden, an opportunity has opened up for creators to start to connect directly again with their audience. The notion that “if you are not the customer, you are the product” has also sunk in, leaving us more willing to pay for online content.
The Rise of the Internet’s Creative Middle Class considers this idea, and whether it’s here for good, or is more a brief moment of sunshine before new content platforms reappear to steal away the proceeds yet again.
Tweaking the NetNewsWire article theme
Sometimes the smallest changes can have a large effect. And so it was with some tweaks I made to how NetNewsWire displays articles on my phone and Mac. All the time I’ve been using NetNewsWire, nearly five years, I’ve been slightly bothered by the use of the standard system font to render articles. It’s just not quite my thing.
So yesterday I decided to work out how to tweak the fonts. I altered the article font to my favourite on-screen reading fonts, IBM Plex Sans on macOS and Saverek on iOS (where you can’t install your own fonts). I also altered the preferred code font to JetBrains Mono, still one of my favourites.
Here’s what I came up with:
Yes: it’s almost identical to the default theme! But, previously, I disliked the font so much that, while I use NetNewsWire all the time on my phone, I didn’t really use it at all on my Mac. But after changing the font to one I like, I find myself coming back to it. We’ll see how long that sticks!
Even with so few differences, changing the font still involves creating a new theme for NetNewsWire. Read on for a short how-to on how to create your own tweaked theme.